
Descriptive statistics is like a trusty companion for data scientists, helping us unravel data’s mysteries. It takes past events and wraps them up neatly in summaries and visuals, so we can see the big picture. Descriptive statistics has become a must-have in many fields, and you’ve probably come across some tools already, like mean, median, or mode. In this article, we’ll dive into the world of descriptive statistics together.
Table of Contents
- What is Descriptive Statistics
- Core Concepts
- Univariate Descriptive Statistics
- Bivariate Descriptive Statistics
What is Descriptive Statistics
Descriptive statistics is just like a snapshot of data, providing an overview of data and capturing its highs, lows and everything in between. Always remember, the foundation of descriptive statistics revolves around three crucial aspects: pinpointing where the data is located, comprehending its extent of spread, and discerning how the values are distributed across the spectrum.
Core Concepts
1. Central Tendency
The central tendency of data just describes where is the center point of a group of data. By knowing the “center” of data, we will have a basic idea of what a typical value should be. Mean, Median and Mode are probably the most commonly used tools to find the central tendency. Here is an example for you to understand the concept.
Let’s say an organization is trying to find out how much a teenager spent in a week nowadays. Therefore, a survey is conducted and here is the result.
| Teenager | Age | Education | Weekly Spent |
|---|---|---|---|
| A | 17 | High School | $110 |
| B | 15 | High School | $150 |
| C | 17 | High School | $100 |
| D | 19 | University | $120 |
| E | 19 | University | $500 |
First of all, let us find out the mean age in the data.
\((17 + 15 + 17 + 19 + 19) / 5 = 17.4\)
By that, we know that most of the data are collected from teenagers around 17.4 years old. Then, we also want to know how much a typical teenager spent weekly, but there is one problem. Notice that the last teenager E has a higher weekly spent compared to the others? If we just calculate the mean directly with the data, we will get $196, which is higher than most of the data. Fortunately, there are other ways to solve this:
- Remove the outlier
- Change to other tools such as median or trimmed mean
One great thing about the median is its ability to stay strong even in the face of outliers or extreme values. To find the median, we need to order the data first. Then, select the value located in the middle from the ordered data. In terms of weekly spent, the ordered data is $100, $110, $120, $150, $500 and the middle value (median) is $120. Just like that, we know that most teenagers spent around $120 a week. If the number of data is an even number, then we could sum the two values in the middle and divide by 2.
Finally, we move on to the Mode. Normally, the mode is mainly used to describe the most frequent value. Therefore, it is the perfect tool to use for categorical data. Simply looking at the table, we can say that most of the teenagers are currently in high school because “High School” appears the most in that column. That’s it, easy right?
Well, it is easy to apply the descriptive statistic concepts on the survey table because it is small. When the data get big enough, it will be time-consuming for us to calculate like how we did just now. That’s why programming comes in handy. Here is an example of how we could use Python to do the work for us.
Finding Central Tendency with Python
import pandas as pd
# Example dataset
data = pd.Series([10, 15, 20, 25, 30, 10, 20, 25])
# Calculate mean
mean = data.mean()
print("Mean:", mean)
# Calculate median
median = data.median()
print("Median:", median)
# Calculate mode
mode = data.mode()
print("Mode:", mode[0]) # Mode can have multiple values, so we select the first one
Variability
After we know where the center point is, we need to know how spread out our data is. Imagine you’re measuring the height of your friends. If they’re all pretty close in height, the variability is low. But if some are super tall and others are shorter, the variability is high. In the world of data, variability helps us see if the numbers are huddled close together or if they’re all over the place. It’s like a peek into how much things change from the average.
In statistics, Range, Variance, and Standard Deviation are the most common metrics to understand how spread out the data is.
1. Range
Among these metrics, “Range” is the most simplest and intuitive one. All we need to do is reduce a data point by the center point (mean or median). For a set of data {1, 2, 3, 4}, both the mean and median are 2.5. The deviations from the mean of each point are:
- \(1 – 2.5 = -1.5\)
- \(2 – 2.5 = -0.5\)
- \(3 – 2.5 = 0.5\)
- \(4 – 2.5 = 1.5\)
From the range value, we can tell how dispersed the data is around the center point.
2. Variance / Standard Deviation
On the other hand, variance and standard deviation are just a fancier way to say how spread out the data is. To understand how it works, let’s have a look at its formula.
\(\text{Variance} = \frac{1}{n} \sum_{i=1}^{n} (x_i – \bar{x})^2\)
\(\text{Standard Deviation} = \sqrt{variance}\)
\(x_i – \bar{x}\), is just the range value and we square it to remove negative signs and amplify differences. Then, sum all the range values between all points and center point and divide the sum by \(n\).
Note that, removing negative signs is to provide a more comprehensive view of the overall dispersion. Furthermore, amplifying differences means the larger the difference between a data point and center point, the stronger impact on the variability measurement.
Finding Variability with Python
import pandas as pd
# Create a sample dataset
data = {'Scores': [85, 90, 78, 92, 88, 70, 95, 82, 80, 88]}
df = pd.DataFrame(data)
# Calculate the mean and standard deviation
mean = df['Scores'].mean()
std_deviation = df['Scores'].std()
# Calculate the variance
variance = std_deviation ** 2
# Print the results
print(f"Mean: {mean}")
print(f"Standard Deviation: {std_deviation}")
print(f"Variance: {variance}")
Univariate Descriptive Statistics
Imagine you’re checking out the scores of your favorite video game. Now, picture this: you’re focusing on one thing at a time – that’s univariate descriptive statistics in action. You’re zeroing in on how each player did individually, like a magnifying glass on their scores. We’re honing in on one specific piece of information, whether it’s scores, heights, or ages.
For example, if we have a table with 3 numeric columns: A, B, and C. When we perform descriptive statistics on the table, we will only focus on any single column at a time. Let’s look at two graphs that plot with one variable.
1. Histogram – Frequency of Data Points Within Intervals
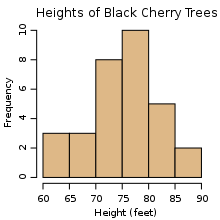
From Wiktionary
2. Box Plot – Distribution of data based on the minimum, first quartile, median, third quartile and maximum

Bivariate Descriptive Statistics
Now, let’s make things a bit more exciting – enter bivariate descriptive statistics! This is when we look at two things and see how they dance together. Imagine checking if the amount of sleep you get affects your test scores. You’re comparing two things – sleep and scores – that’s bivariate!
With bivariate stats, we can see if there’s a connection between these two things. Does more sleep lead to better scores? Or is there no dance between them? It’s like studying whether rainy days mean people drink more hot chocolate – are they related or just doing their own thing?
Here are two graphs used for bivariate descriptive statistics
1. Scatter Plot

2. Correlation Matrix – Displaying the correlation coefficients between multiple pairs of variable

